
智源研究院正式推出了他们的新一代多模态世界模型 Emu3,该模型最为显著的特色在于,其仅凭借对下一个 token 的预测能力,便能够在文本、图像和视频这三种不同模态中实现理解和生成。


在图像生成领域,Emu3能够依据视觉 token 来预测并生成高质量的图像。这就意味着用户能够期待具有灵活分辨率以及多样风格的图像。

而在视频生成方面,Emu3呈现出了一种全新的工作模式,有别于其他模型依靠噪声来生成视频,Emu3通过顺序预测的方式直接生成视频。这种技术上的进步促使视频生成变得更加流畅且自然。

在图像生成、视频生成以及视觉语言理解等诸多任务当中,Emu3的表现均超越了许多广为人知的开源模型,诸如 SDXL、LLaVA 和 OpenSora。其背后依托的是一个强大的视觉 tokenizer,能够把视频和图像转化为离散的 token,如此设计为统一处理文本、图像和视频开辟了新的路径。
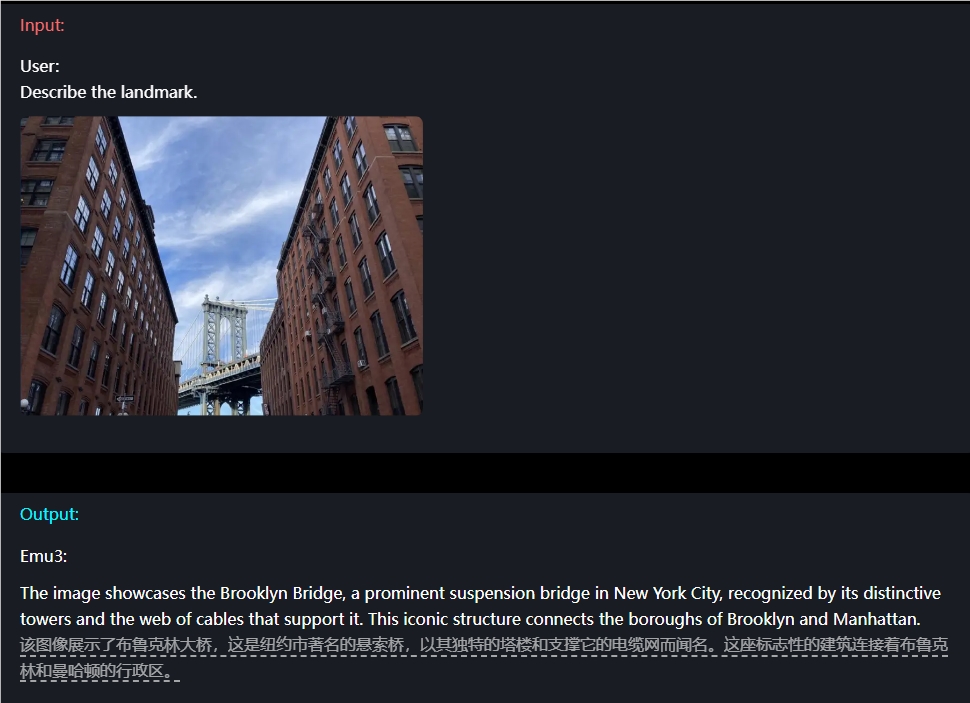
例如,在图像理解方面,用户仅需简单输入一个问题,Emu3就能够精确描述出图像的内容。
Emu3还拥有视频预测的能力。当提供一个视频时,Emu3能够依据已有的内容,推测接下来可能会发生的情况。这使得它在模拟环境、人类和动物行为等方面展现出了强大的能力,能够让用户获得更加真实的互动体验。

另外,Emu3的设计灵活性也令人眼前一亮。它可以与人类的偏好直接进行优化,从而使得生成的内容更贴合用户的期望。而且,Emu3作为一个开源模型,引发了技术社区的广泛热议,许多人觉得这一成果将会彻底改写多模态 AI 的发展态势。
项目网址:https://emu.baai.ac.cn/about
论文:https://arxiv.org/pdf/2409.18869
重点概括:
🌟 Emu3凭借对下一个 token 的预测,达成了文本、图像和视频的多模态理解与生成。
🚀 在众多任务当中,Emu3的性能优于多款知名开源模型,彰显出了强大的实力。
💡 Emu3的灵活设计以及开源特性,给开发者创造了新的机遇,有望推动多模态 AI 的创新与进步。
内容由用户投稿,如若转载,请注明出处:https://aiczwd.com/blog/archives/560